I am a second-year PhD student in UC Berkeley, advised by Prof.Kurt Keutzer. My research interest is about efficient training and inference of large language models and diffusion models. I graduate from Yao Class, Tsinghua University, led by Prof.Andrew Yao.
I work closely with Prof.Song Han in MIT. Back in Tsinghua University, I was fortunate to be advised by Prof.Jianfei Chen and Prof.Jun Zhu. I was also fortunate to be advised by Prof.Sheng Wang in University of Washington.
Feb 2024 - Aug 2024
Beijing, China
Conduct Research about FP8 Training for Large Language Models. Advised by Prof.Song Han.
Feb 2024 - Aug 2024
2024-Present Ph.D in Computer Science, advised by Prof.Kurt KeutzerGPA: 4 out of 4Publications:
Extracurricular Activities:
| ||
2020-2024 B.E. in Yao Class, Computer Science. Advised by Prof.Jianfei Chen and Prof.Jun ZhuGPA: 3.83 out of 4 |
We propose a training-free sparse attention framework that uses semantic-aware permutation - clustering and reordering tokens via k-means based on semantic similarity - to achieve a new pareto-frontier in speed-quality tradeoff.
We identify the spatial head and temporal head pattern in attention map and propose to use sparse attention to accelerate. Achieves up to 2.28x and 2.33x end-to-end speedup on CogVideoX-v1.5 and HunyuanVideo.
We propose a self-speculative decoding framework, QuantSpec, to speedup long-context inference. QuantSpec maintains high acceptance rates (>90%) and reliably provides consistent end-to-end speedups upto ∼ 2.5×.
We propose Dynamic range expansion for FP8 optimizer, and propose FP8 precision flow for FP8 activations. Achieve Lossless performance, end-to-End 1.54x memory reduction and 1.43x training speedup over BF16.
We propose a new method for efficient and accurate transformer pretraining with INT8 data flow and per-block quantization. Demonstrate effectiveness on GPT2-774M model. Achieve End-to-End 1.42x training speedup and 1.49x memory reduction.
Propose Hadamard Quantizer and Leverage Score Sampling to enable INT4 Precision Matmul in training for speedup. Both the forward and backward pass are quantized into INT4 precision for maximized speedup. Outperforms all existing 4-bit training baselines.
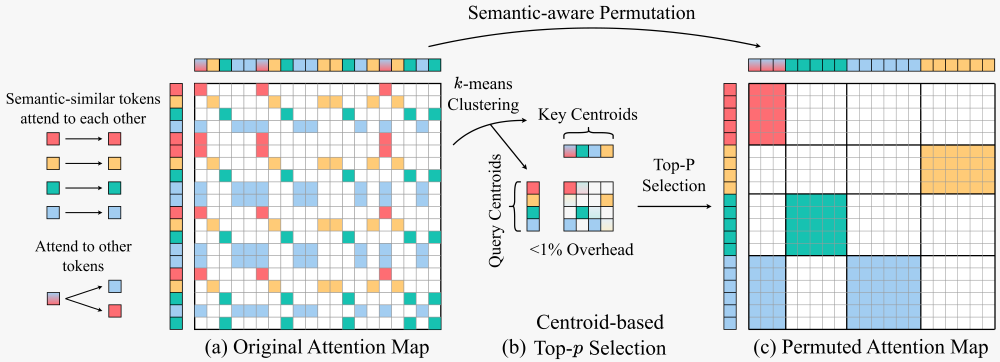
We propose a training-free sparse attention framework that uses semantic-aware permutation - clustering and reordering tokens via k-means based on semantic similarity - to achieve a new pareto-frontier in speed-quality tradeoff.
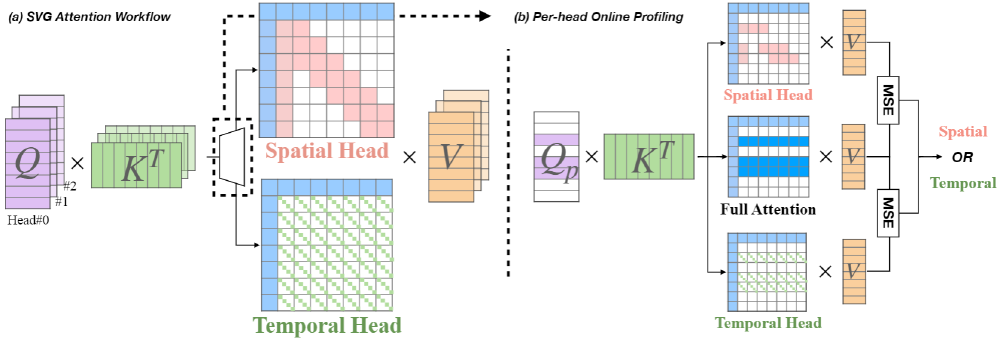
We identify the spatial head and temporal head pattern in attention map and propose to use sparse attention to accelerate. Achieves up to 2.28x and 2.33x end-to-end speedup on CogVideoX-v1.5 and HunyuanVideo.
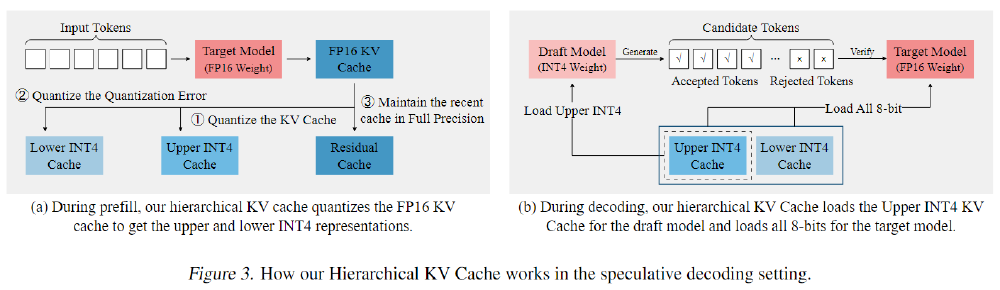
We propose a self-speculative decoding framework, QuantSpec, to speedup long-context inference. QuantSpec maintains high acceptance rates (>90%) and reliably provides consistent end-to-end speedups upto ∼ 2.5×.

We propose Dynamic range expansion for FP8 optimizer, and propose FP8 precision flow for FP8 activations. Achieve Lossless performance, end-to-End 1.54x memory reduction and 1.43x training speedup over BF16.

We propose a new frontier of visual language models, NVILA, to achieve reduces training costs by 4.5X, fine-tuning memory usage by 3.4X, pre-filling latency by 1.6-2.2X, and decoding latency by 1.2-2.8X.

We propose SpargeAttn, a universal sparse and quantized attention for any model inference. Our method uses a two-stage online filter to select the most important tokens.
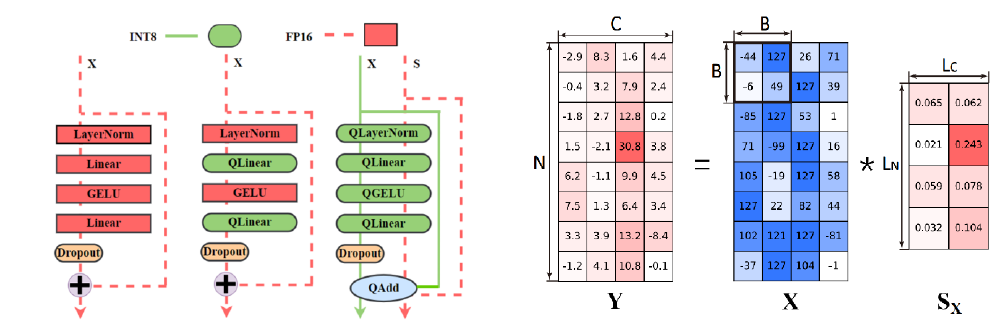
Propose to INT8 precision flow and per-block quantization to enable INT8 pretraining of transformers. Demonstrate effectiveness on GPT2-774M model. Achieve End-to-End 1.42x training speedup and 1.49x memory reduction.
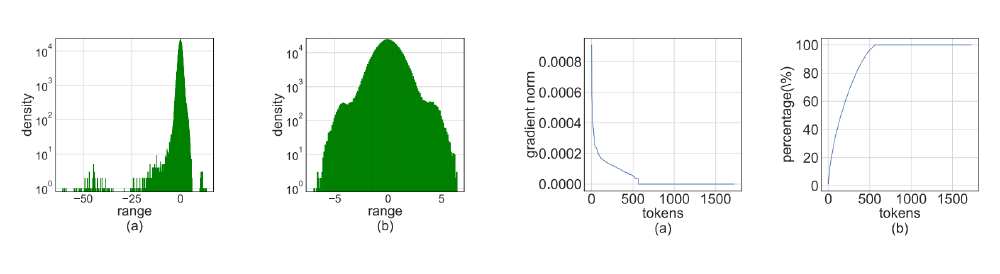
Propose Hadamard Quantizer and Leverage Score Sampling to enable INT4 Precision Matmul in training for speedup. Both the forward and backward pass are quantized into INT4 precision for maximized speedup. Outperforms all existing 4-bit training baselines.