
t = 1
A perspective on long-horizon video generation
To stay consistent over a long video, a model has to remember its own past. In a Video Diffusion Model, that memory is the KV cache, which grows with every frame. Since a single frame can contain thousands of tokens, that KV cache balloons far faster than in text, and keeping all of it soon leads to Out-Of-Memory issues on GPUs. However, long video generation or world model cannot afford to forget. When the model loses access to the history it needs, consistency starts to break: a character slowly drifts into someone else, or a room quietly rearranges itself over time. These failures may look like visual artifacts, but underneath they are actually memory failures — the model no longer has faithful access to its own past. We call this the Forgetting Wall.
What ultimately limits long video generation is not only how well the model can predict the next frame, but how much of its history it can afford to keep and use. In this blog, we discuss what the Forgetting Wall is, why it is hard, how it actually fails in long video generation, and what possible solutions look like — from sliding windows to compression. At the end, we point to one thing we tried: QuantVideoGen [1].
If you ask why we can't yet generate long, coherent video, the most common answer is some version of “we need more compute” — bigger models, longer training [2], more frames per second of generation. That answer isn't exactly wrong, but it points at the wrong wall.
For a while, the hard part of video generation was really per-frame quality, and that has largely been solved, so individual frames now look great [3][4]. The problem is, a clip can score near the top on per-frame quality and still fail badly on world consistency, and the two turn out to be largely uncorrelated. The frontier has moved to length and interactivity: generating minute-scale clips, and building world models you can steer and move around inside [5]. However, when you push on length, the failure you hit is not that the model runs out of compute. It's that the model forgets. The character who walked off-screen comes back wrong. The room quietly rearranges itself. Turn the camera away in a world model and turn it back, and the world has been reinvented.
Those aren't quality bugs. They're memory bugs. The Forgetting Wall for long-horizon video is the model's ability to remember its own past, and that turns out to be a surprisingly hard constraint.
Let's be concrete about what memory means for these models. An autoregressive video model generates frame by frame [6], and each new frame attends to what came before through the transformer's attention. To do that, it stores a key and a value for every past token (the KV cache). The KV cache is the model's memory of the video so far. If a detail isn't in the cache, the model has no way to be consistent with it.
The problem is how that cache scales. It grows linearly with the number of tokens generated — and video is brutally token-hungry. A single frame is worth thousands of tokens, so a clip that is “only” a few hundred frames long carries a KV cache equivalent to a text context of millions of tokens. This is the same long-context problem that has consumed LLM research for years, but video arrives at the wall much faster and hits it much harder. And not all of that history plays the same role: nearby frames carry the fine continuity of motion, while distant ones mostly sit there as context the model must occasionally recall — an asymmetry we'll come back to.



Here is the tension at the heart of the Forgetting Wall. Long-term consistency requires long-term memory: if a face leaves the frame and reappears one minute later, the model can only keep it consistent if its KV cache still holds what that face looked like one minute ago. But keeping all of that memory, at full precision, eventually overflows the hardware. So you're caught between two bad options:
Remember everything, and run out of memory. Or bound the memory, and start forgetting.
What makes this genuinely hard is a second problem layered on top: you don't know in advance which memories you'll need. A token from five seconds ago might be irrelevant, or it might be the only place the model recorded how the objects on a table were arranged. Any scheme that throws away “unimportant” history is making a bet about the future, and long-range dependencies are exactly the case where that bet is hardest to get right. It's very likely that the detail dropped to save memory turns out to be exactly the one the model needed to stay consistent later.
The abstract problem becomes obvious the moment you watch a model that has mismanaged its memory. The symptoms are consistent across systems:
All three are the same underlying fault seen from different angles: the relevant past was not available, accurately, in the cache.


The difficulty isn't only that memory is expensive. It's that saving memory and staying consistent pull in opposite directions. Nobody has fully solved this, but it's worth seeing the whole map, because the proposals on the table are really different ways of confronting the dilemma from Section 3. They fall into several families.
The most direct idea is to store less of the past. Sliding-window and local attention only look back a fixed distance [6][7]: memory is bounded, but the model is blind to anything older than the window. Attention sinks and streaming methods keep a few anchor tokens alongside the window so generation stays stable as it slides — a fix for stability, not for long-range recall [8][9]. KV eviction and learned sparse routing try to route each query to just the slice of history it needs [10]. They all rely on the same assumption: that whatever they drop will not be needed later. The hard part is that this is impossible to predict in advance — there is no reliable way to tell, at the moment you drop a token, whether some much later frame will turn out to depend on it. So every fixed rule for what to discard is really a bet about a future the model cannot see, and over a long horizon that bet is one that long-range dependencies routinely lose.

A second family changes the math so memory stops growing at all. Linear attention and state-space models [11] fold the entire history into a fixed-size state, so cost stays constant no matter how long the video runs. Sana-Video [12] and Sana-WM [13] are concrete examples. They build their video generator on linear attention instead of the usual quadratic attention, so rather than caching a key and value for every past token, they keep a single fixed-size state and update it as each new frame arrives. FramePack [14] reaches the same fixed budget differently: it compresses each input frame's context by importance, keeping recent frames detailed and packing older ones into fewer tokens, so the total context length never grows. Memory then stays flat as the clip grows longer. It's an elegant ceiling on memory, but a fixed state is a lossy summary: the precise details that long-range consistency depends on are often the first thing a bounded summary washes out.

The third family refuses to throw anything away, and instead makes the cache cheaper to hold: KV-cache compression and quantization store every token, just at lower precision. This is the direction I find most promising for video, for one concrete reason: video's KV cache is enormously redundant. Adjacent frames look alike, and neighboring regions within a frame look alike, so there is far less independent information in the cache than its raw size suggests. The catch is that this redundancy is buried under a messy, irregular distribution, so it takes a carefully designed compression algorithm to expose that structure to maintain a high quality.

And you can't simply borrow the compressors built for text [15]. They were designed for one-dimensional token streams, not for video's spatiotemporal structure — so a strong LLM KV-quantizer might degrade (Figure 4). The opportunity is real, but it has to be taken on video's own terms.
QVG is our take on this third family: a KV-cache quantization method built around video's structure rather than borrowed from text. It first subtracts what neighboring tokens share (Semantic-Aware Smoothing) and then refines the leftover residual coarse-to-fine (Progressive Residual Quantization), which lets a pretrained model run on a 2-bit KV cache — up to 7× less memory at under 4% latency overhead, with quality essentially intact. It's training-free and open-source; details are in the paper and code.
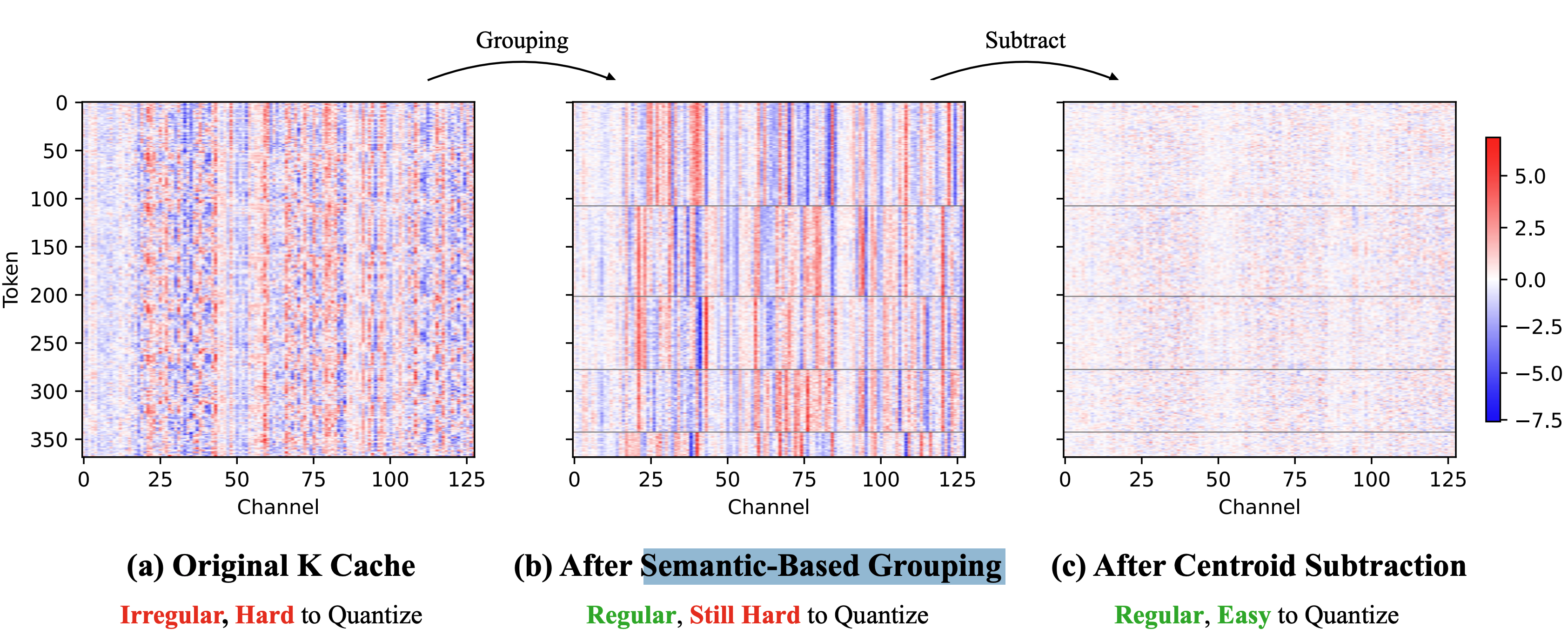
There are a few other directions too. One is to shrink the cache by adopting a more aggressive video VAE to encode each frame into far fewer latent tokens. Deep-compression autoencoders such as DC-AE [16] reach compression ratios about 4× higher than earlier VAEs, and since the KV cache scales inversely with the compression ratio, that 4× cuts the cache to roughly a quarter [17]. The other is to relocate the cache by keeping the full KV history in abundant CPU / host memory and stream each slice back to the GPU when attention needs it. Nothing is forgotten or approximated, but moving the cache across the PCIe bus on every step is slow, so for real-time, interactive generation the latency is usually prohibitive.
As video models become world models (interactive, long-lived, and something an agent can act inside), memory becomes the defining constraint, playing the same role for world models that context length plays for LLMs. How much of the past a model can afford to remember sets a hard ceiling on how long, coherent, and controllable its world can be.
The answer is probably not a single trick. Recent frames need high-resolution local memory. Distant history may need to be compressed, summarized, or retrieved only when it matters. Spatial structure may eventually live in a more explicit world representation. In other words, future video models will likely need a memory hierarchy, not just a longer cache.
But before we get there, one thing seems clear: forgetting is too damaging. If long video is to stay consistent, the model needs a way to keep far more of its past than today's systems can afford.
If you find it helpful, please cite:
@article{xi2026quant,
title = {Quant VideoGen: Auto-Regressive Long Video Generation via 2-Bit KV-Cache Quantization},
author = {Xi, Haocheng and Yang, Shuo and Zhao, Yilong and Li, Muyang and Cai, Han and Li, Xingyang and Lin, Yujun and Zhang, Zhuoyang and Zhang, Jintao and Li, Xiuyu and others},
journal = {arXiv preprint arXiv:2602.02958},
year = {2026}
}
@misc{xi2026memory,
title = {The Forgetting Wall in Video and World Models},
author = {Xi, Haocheng and Yang, Shuo and Zhao, Yilong and Li, Muyang and Cai, Han and Li, Xingyang and Lin, Yujun and Zhang, Zhuoyang and Zhang, Jintao and Li, Xiuyu and others},
year = {2026},
month = {June},
url = {https://haochengxi.github.io/posts/forgetting-wall/},
note = {Blog post}
}